Fig 1 — OwnScrape replaces Apify, Bright Data, Diffbot and runs natively on the Own360 control plane.
Why OwnScrape exists
Every team scrapes something — competitor prices, regulatory registers, supplier portals, market listings — and almost every team does it with brittle scripts on someone's laptop or a rented scraping API that sees all your targets. OwnScrape exists to make web capture a governed, self-hosted capability: recorded once, scheduled forever, and auditable like everything else on the platform.
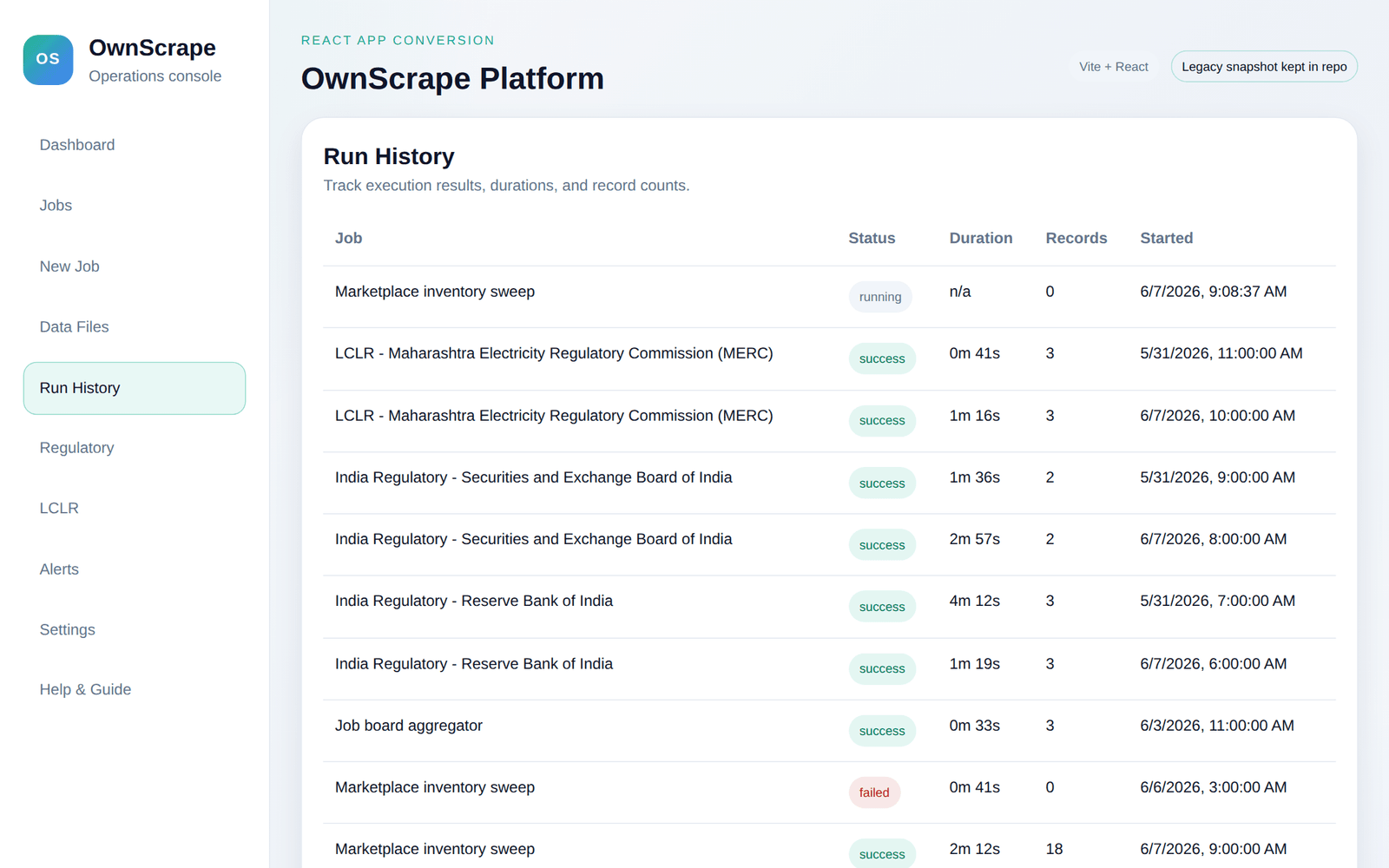
The workflow is deliberately simple. A Chrome-extension recorder turns a manual browsing session into a repeatable scrape definition; a Playwright headless backend executes it on a schedule with SSRF guards, proxy rotation, and retries; and the results land as governed datasets in OwnData — or export to Sheets — with run history you can inspect job by job.
Capture the open web. On a schedule. Under control.
What it replaces
Most teams reach OwnScrape after running into the limits of the legacy stack:
- Apify — the recorder-to-scheduled-job workflow lives inside your perimeter, so target lists, session cookies, and captured data never transit a third party.
- Bright Data — batch concurrency, proxy rotation, and per-run diagnostics are part of the backend rather than a metered add-on.
- Diffbot — preserved as a familiar reference point but no longer required for the workflow.
Capabilities in detail
- Flow Recorder. A Chrome-extension recorder turns a manual browser flow into a repeatable scrape definition — no code required.
- Job Scheduler. Cron-driven jobs with run history, status, and retry. Captures happen on your cadence, not someone else's queue.
- Headless Backend. Playwright execution with SSRF guard, proxy rotation, and batch concurrency — hardened for hostile pages.
- Regulatory Tracking. Watch documents and pages, diff on change, and alert downstream apps the moment something moves.
- Governed Output. Results land as datasets in OwnData or export to Sheets — with lineage and access controls included.
The numbers that matter
Who uses OwnScrape
Growth: Turn target sites into a steady lead feed that lands in OwnCRM automatically. Compliance: Watch regulatory pages and get alerted the moment a rule or filing changes. Data Engineer: Schedule captures, monitor runs, and pipe results into the data plane — no brittle scripts.
Frequently asked questions
What is OwnScrape?
OwnScrape is the Own360 product for “Capture the open web. On a schedule. Under control.” in the Engineering layer — self-hosted web-data capture and browser automation — turn any site, portal, or document into a governed, scheduled feed the rest of Own360 can read. A Chrome-extension recorder plus a Playwright headless backend, with SSRF guards, retries, and full run history.
How does OwnScrape fit into the Own360 stack?
OwnScrape runs on top of the Own360 control plane — sharing identity, permissions, audit, and workflow services with every other Own product. There is no separate SSO setup, separate audit log, or separate integration layer. The same governance and event bus apply.
Is OwnScrape self-hosted?
Yes. The entire Own360 platform — including OwnScrape — is designed to run inside your VPC, your on-prem data centre, or a sovereign cloud. Source-available with perpetual licensing; no per-seat tax, no data egress, no telemetry leaving your boundary.
Related products in the Engineering layer
- OwnData — Federate. Govern. Stream. Serve.
- OwnETL — Extract. Transform. Validate. Land.
- OwnFlow — Trigger. Branch. Approve. Automate.
See it live
OwnScrape is part of the Own360 platform demo. Get in touch for a walkthrough, or browse the rest of the product stack to see how the layers compose. Full specs, metrics, and licensing live on the OwnScrape product page.